Parallel Programming With CUDA Tutorial (Part-2: Basics)

In this tutorial, we will start coding. We will do both the sequential and the parallel version of the problem we want to solve. We will also give an overview of the general architecture of how threads are organized. We will also do some performance analysis.
Hardware Specification: I am using an Nvidia 1050ti 4GB. And a Core i5–7500 CPU @ 3.40GHz with 16GB DDR4 2400MHz memory. Both of them are comparable in price; Nvidia GPU being cheaper in price.
First, let’s define the problem we are going to solve. It is quite a difficult one 😉:
Problem: Given two array X and Y of N floating point numbers, add the number in each index of X with the number in corresponding index of Y and save the result in Y. i.e. Y[i]=X[i]+Y[i] where 0≤i<N
I have chosen this problem because it is easy to understand in both in sequential and parallel form. Now let’s write the code for sequential version and benchmark it.
Sequential Version:
The function add takes input N, X, Y and completes the task in the problem. It does not need to return any value as we will be sending Pointer of array X and Y. The add function is given below:
void add(int N, float *X, float *Y)
{
for (int i=0; i<N; i++)
{
Y[i] = X[i] + Y[i];
}
}We will run our add function 10 times and will calculate average execution time. The full code is given below:
We took N=2²⁷. On Average, it took the CPU about 332.82 ms. Now let’s dive into parallel programming.
Parallel Version:
Algorithm:
First, let’s talk about our strategy on making the algorithm parallel. Here is what we will do:
- We will take T threads.
- For thread number t where 0≤t<T it will work on index t+aT where a≥0 and t+aT<N.
- An example will make it clear. Suppose we take 32 thread. So T=32.
- Thread number 0 will work on index 0+0*32, 0+1* 32 , 0+2*32 i.e. 0,32,64,96,128… and so on while t+aT<N.
- Thread number 1 will work on index 1+0*32, 1+1* 32 , 1+2*32 i.e. 1,33,65,97,129… and so on while t+aT<N.
- This way we will divide the array among threads equally.
Now we have to implement this on GPU. Let’s start doing it by creating an add function that each thread on our GPU will run. We will do it by following the pseudo code below:
ADD(N,X,Y):
t = Current thread number
T = Total number of threads
i = t
while i<N:
Y[i] = X[i]+Y[i]
i=i+TSeeing this pseudo code we can see that we will need the Current thread number as well as the total number of threads. It is quite easy to get that information with CUDA. But to understand it we first have to know the general architecture of how threads are organized.
Organization of Threads:
All our Threads are organized in Blocks. We can organize our threads in 1,2 or 3-dimensional blocks. Blocks are organized in Grids. We can organize our blocks in 1,2 or 3-dimensional grids. In the picture below we have 2D blocks of threads organized in a 2D grid of blocks:
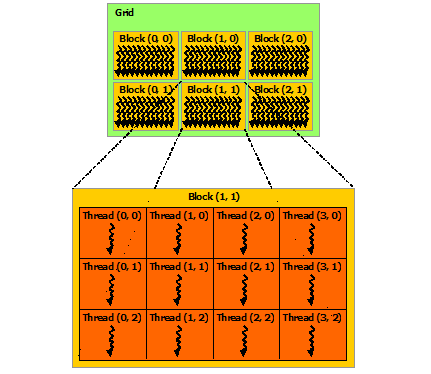
A function that the GPU can run, is called a kernel in CUDA. A GPU can run many concurrent Kernels each of which uses a grid. But how many grids can we have and how many blocks per grid and how many threads per block? The maximum number of resident grids depends on your GPU’s Compute capability. Numbers are given in the table below:

In this tutorial, we will use one-dimensional thread blocks and only one block in our grid for simplicity.
Implementation:
- How to tell the GPU that a function is a Kernel?
Add __global__ before it. so void add(int N, float *X, float *Y) becomes __global__ void add(int N,float *X, float *Y)
2. How to get Current thread number and the Total number of threads?
There are 4 variables each thread can access which contains information about the organization of threads and current thread. They are:
- threadIdx : Id of the current thread.
- blockIdx : Id of the current block.
- blockDim : Size of each dimension of the current block.
- gridDim : Size of each dimension of the current grid.
All of these are dim3 structure. we can use dot notation to access variable x,y,z which contains the information of the corresponding dimension. Example: threadIdx.x
That is all we need to implement our new add function:
__global__
void add(int n, float *x, float *y)
{
int t = threadIdx.x;
int T = blockDim.x;
for (int i = t; i < n; i += T)
y[i] = x[i] + y[i];
}We will need 3 more things to finish up our code.
- cudaMallocManaged(): Allocate Unified Memory accessible from CPU or GPU.
- cudaDeviceSynchronize(): Wait for GPU to finish executing kernel.
- add<<<dim3(1,1,1), dim3(T,1,1)>>>(N, X, Y): To call add kernel. The first dim3(x,y,z) specifies the dimensions of the grid and the second one specifies the dimensions of the block. Since we are going to use one block in our grid and one-dimensional block with T threads we used
<<<dim3(1,1,1),dim3(T,1,1)>>>.
And we are done. With all this information we can write the full code as shown below. I have added some additional code to calculate performance and save it to a CSV file which you can skip.
Performance Analysis:
Using 1 GPU thread it takes about 22042.01 ms which is about 66 times slower than the CPU. But as we increase the number of threads it drops quite quickly at first and starts slowing down after it reaches about 400 threads. Using 1024 threads we can reach 46.54 ms which is about 7.1 times faster than the 1 CPU Core(I have neither exhausted the CPU nor the GPU). and about 475 times faster than using just one Thread. As we can see the relation between execution time and thread count is not linear. We can sum up our performance analysis with the graph below.

Note: In the graph, for GPU we started showing the thread count starts from 32 because for 1 thread execution time is too high.
What if we want to use multiple blocks to speed up the process even faster. Just edit the add function as shown below:
__global__
void add(int N, float *X, float *Y)
{
int t= blockIdx.x * blockDim.x + threadIdx.x;
int T = blockDim.x * gridDim.x;
for (int i = t; i < n; i += T)
Y[i] = X[i] + Y[i];
}Why are we calculating t and T this way? That is a exercise for you. Try to understand the definition of those 4 variable given above.
- With 1 block each with 1024 threads, it is 46. 54 ms.
- With 2 blocks each with 1024 threads, it becomes 27.8 ms.
- With 4 blocks each with 1024 threads, it becomes 19.7 ms.
- With 8 blocks each with 1024 threads, it becomes 17.7 ms.
- With 16 blocks each with 1024 threads, it becomes 17.6 ms.
- With 32 blocks each with 1024 threads, it becomes 17.4 ms.
- With 256 blocks each with 1024 threads, it becomes 17.5 ms.
After 8 blocks it does not help much. We will see in future problem how we can utilize blocks properly. Using 8*1024=8196 threads we become about 20 times faster than 1 CPU core. Graph of Performance analysis with different block size is given below.

You can find all my codes here:
Thanks for reading.
Update: Here is the link for part-3
